【汉王OCR文字识别软件免费版】汉王文字识别软件免费下载 v2022 绿色电脑正式版
软件介绍
汉王OCR文字识别软件免费版是一款非常经典的办公辅助工具,现在很多软件都自带了OCR识别技术,而早些年则需要独立的识别软件进行文字识别,汉王PDF OCR文字识别软件则是其中的佼佼者,玩家可以通过这款软件对文档上的文字进行快速识别,有效提升用户的办公效率。
汉王文字识别软件软件还自带了有PDF编辑功能,这款软件对比同类软件拥有更好的文字识别率以及识别速度,并且有多种格式可以用来保存识别出来的文字,让用户可以轻松对不可编辑文档进行文字内容提取。
软件特色
印刷体字符识别
1.多国文字识别:支持中、日、韩、法、意、德、西班牙、瑞典、葡萄牙、丹麦、荷兰、挪威等国文字的识别。
2.手写体数字识别: 具有3个独立的识别引擎,高识别率。
3.支持有规律的复杂表单、票据的识别。
手写体字符识别
1.支持自由手写体字符识别。
2.支持分格类手写体字符识别。
3.可自动判别印刷体与手写体,并分别进行识别。
4.支持各类平台的接口调用,支持可定制的开发服务,支持私有云、公有云的搭建。
少数民族字符识别
汉王在识别我国少数民族语言文字方面一直走在国内前茅,拥有多项创新。
1.支持维哈柯文识别
2.支持满文识别
3.支持藏文识别
自然场景拍照识别
利用深度学习技术,汉王在自然场景下拍照识别中取得重大进步,可以在任意照片中自动检测到文字区域并进行识别,支持中英文及多种变形字体。
汉王OCR文字识别软件功能
公式字符识别
1.输入图像格式:支持扫描图像和拍照图像两种取图方式。
2.输入版面格式:能自动区分文本和公式区域。
3.支持公式类型:中小学阶段的“数学公式、物理公式、化学公式”。
4.支持文本类型:中文简体、繁体、英文、特殊字符。
复杂表格识别
汉王票据识别技术包含票据表格核心处理技术,根据用户预先定义的票据表格单证类别自动区分待录入的票据、表格单证的类别,自动定位票据待识别的区域并完成自动识别,输出结构化数据。
卡片识别
<身份证/银行卡/营业执照/行驶证/驾驶证/名片>可识别实际拍摄的彩色或灰度名片(彩色证件需彩色图片),可自动分析证件结构,理解证件内容,将证件信息的识别结果按照相应类别而输出。
票据识别
<发票/交通票(火车票、行程单、出租车票)/包裹面单/银行类票据>汉王票据识别技术包含票据表格核心处理技术,根据用户预先定义的票据表格单证类别自动区分待录入的票据、表格单证的类别,根据客户预先定义内容自动定位票据待识别的内容。不需人工参与可以快速大批量多种类的识别大量单据表格单证信息。
条码识别
汉王条码识别技术覆盖了市面上主流的一维码和二维码,以及金融业支票用的E13B码等行业码字。SDK开发工具包可以提供多种一维二维条码的制码及解码核心,以便用户嵌入自身业务系统中。
汉王OCR文字识别软件使用方法
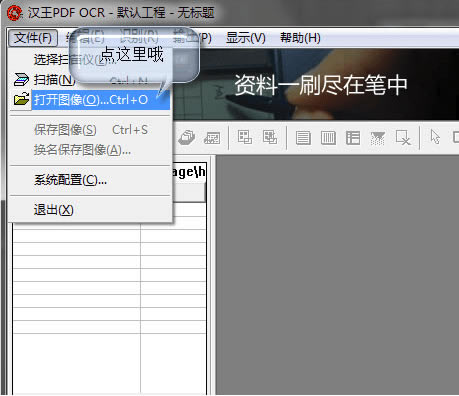
1、首先我们打开在电脑上安装好的汉王PDF OCR软件,然后就可以进入到软件的主界面,如下图所示,我们可以先点击文件选项,然后会出现下拉框,我们选择点击“打开图像”选项,你可以可以直接使用打开头像的快捷键,快捷键Ctrl+O。
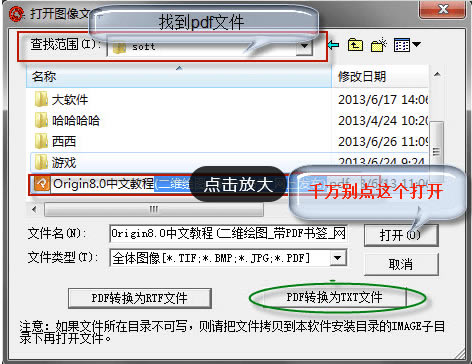
2、接下来我们就会进入到打开头像文件界面,如下图所示,我们需要找到你在电脑上的PDF文件,找到后我们点击PDF文件选中它,接下来点解界面下方的“PDF转换为TXT文件”选项,然后进入下一步。这里需要注意的是不要点击界面中的“打开”选项。
3、然后我们就进入到PDF转换为TXT界面,如下图所示,我们在界面上选择转换的页面,你可以选择转换的范围,从第几页开始到第几页结束,选择完成后我们在界面的下方还需要选择保存目录,点击浏览选择合适的位置后再点击确定。
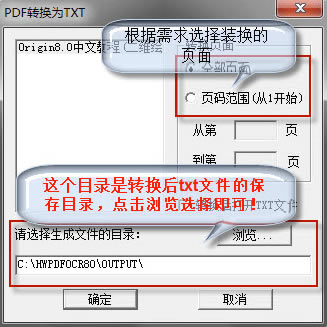
4、等待转换完成后,我们就可以在设置的保存位置找到转换完成后的TXT文件了。转换的时间是根据你转换的数量来决定的,数量少,转换快,数量多,转换的就比较慢。
汉王OCR文字识别软件运行流程
1.图像输入
汉王PDF OCR对于不同的图像格式,有着不同的存储格式,不同的压缩方式,目前有OpenCV、CxImage等开源项目。
2.预处理
汉王ocr文字识别软件功能主要包括二值化,噪声去除,倾斜较正等。
3.二值化
对摄像头拍摄的图片,大多数是彩色图像,彩色图像所含信息量巨大,对于图片的内容,可以简单的分为前景与背景,为了让计算机更快的、更好地识别文字,我们需要先对彩色图进行处理,使图片只前景信息与背景信息,可以简单的定义前景信息为黑色,背景信息为白色,这就是二值化图。
4.噪声去除
对于不同的文档,对噪声的定义可以不同,根据噪声的特征进行去燥,就叫做噪声去除。
5.倾斜校正
由于一般用户,在拍照文档时,都比较随意,因此拍照出来的图片不可避免的产生倾斜,这就需要文字识别软件进行较正。
6.版面分析
汉王ocr文字识别软件可以将文档图片分段落,分行的过程就叫做版面分析,由于实际文档的多样性,复杂性,因此,目前还没有一个固定的,最优的切割模型。
7.字符切割
由于拍照条件的限制,经常造成字符粘连,断笔,因此极大限制了识别系统的性能。
8.字符识别
这一研究已经是很早的事情了,比较早有模板匹配,后来以特征提取为主,由于文字的位移,笔画的粗细,断笔,粘连,旋转等因素的影响,极大影响特征的提取的难度。
9.版面还原
人们希望识别后的文字,仍然像原文档图片那样排列着,段落不变,位置不变,顺序不变地输出到Word文档、PDF文档等,这一过程就叫做版面还原。
10.后处理、校对
汉王PDF OCR根据特定的语言上下文的关系,对识别结果进行校正,就是后处理。
……
点击下载办公软件 >>本地高速下载
点击下载办公软件 >>百度网盘下载