【JasperReport下载】JasperReport报表生成工具 v6.7.0 绿色中文版
软件介绍
JasperReport是一款免费开源的报表生成工具,我们可以通过这款软件来制作各种复杂的报表。而且JasperReport中文版还能够将制作好的报表文件转换成PDF,HTML,或者XML格式。这款软件是JAVA设计人员经常会使用到的重要工具之一。
JasperReport软件简介
JasperReport是一个强大、灵活的报表生成工具,能够展示丰富的页面内容,并将之转换成PDF,HTML,或者XML格式。该库完全由Java写成,可以用于在各种Java应用程序,包括J2EE,Web应用程序中生成动态内容。
Jasperreport是开源的,这给我们带来很大方便,但文档收费,可以理解。
它还有一个相关的开源工程IReport。
IReport是一个图形化的辅助工具,能弥补JasperReport的缺陷:JasperReport仅提供了可使用的类库,而未提供更好的开发工具。它们配合使用将会更大程度的提高效率。
JasperReport基本架构
JasperReport借由定义于XML文档中的report design进行数据组织。
这些数据可能来自不同的数据源,包括关系型数据库,collections,java对象数组。
通过实现简单接口,用户可以将report library插入到订制好的数据源中。
JasperReports的报告模板可以以iReport之类的工具来制作,只要把报告储存成XML格式,就可以让JasperReport阅读,然后再编译成为.jasper档。
JasperReports是世界上最流行的开源报告引擎。它是完全用Java编写的,它是能够使用的数据来自任何类型的数据源,并生成像素级的文档,可以查看、打印或导出在多种文档格式,包括HTML、PDF、excel、Openoffice和doc。
JasperReport使用方法
第一步:XML解析
JasperReport使用SAX2.0 API对XML文件进行解析。然而,这并不是必须的,用户可以在执行其自行决定使用哪一种XML解析器。
JasperReport使用org.xml.sax.helpers.XMLReaderFactory类的createXMLReader()来获得解析器实例。在这种情况下,就像在SAX2.0文档中说的那样,在运行期,把Java系统属性org.xml.sax.driver(这是属性的key)的值(value)设定为SAX driver类的全限定名是必要的。用户可以通过两种方法做到这一点,我稍后将解释全部两种方法。如果你想使用不同的SAX2.0XML解析器,你需要指定相应的解析器类的名字。
设置系统属性的第一种方法是在你启动Java虚拟机的时候,在命令行使用-D开关:java ?Dorg.xml.sax.driver=org.apache.serces.parsers.SAXParser mySAXApp sample.xml
在JasperReport提供的所有例子中,都采用ANT构建工具来执行不同的任务。我们通过使用内置的 task中的元素来提供这一系统属性:
第二种设置系统属性的方法是使用java.lang.System.setProperty(String key, String value)
System.setProperty(“org.xml.sax.driver”,” org.apache.xerces.parsers.SAXParser”);
Jsp/compile.jsp和web-inf/class/servlets/CompileServlet.java文件提供了这方面的例子。
注:对于第二种方法,我要说些题外话。有关于JVM的系统属性(我们可以通过System.out.println(System.getProperty(“PropertyKey”)来查看),可以在运行期像上面说所得那样用System.setProperty(“propertyKey”,”propertyValue”);来进行设置。但是一旦JVM已经启动之后,其内建的系统属性,如user.dir,就不能再被更改。奇怪的是我们仍可以用System.setProperty()方法对其进行设置,而在用System.out.println(System.getProperty())方法进行查看的时候发现,其值已经更改为我们设置的值,但事实上我们设置的值不会起任何作用。所以对于内置的属性,我们只能通过-D开关在JVM执行之前进行设置。对于org.xml.sax.driver,由于它不是系统内建属性,所以仍然可以在JVM启动之后加以设置。更详细的信息可以参考王森的〈Java深度历险〉。
第二步:编译报表设计(Report Designs)
为了生成一个报表,用户需要首先生成报表的设计(report’s design),生成方法或采用直接编辑XML文件,或通过程序生成一个net.sf.jasper.engine.design.JasperDesign对象。本文中,我将主要采用编辑XML文件的方法,因为这种方法在目前是使用JasperReport类库的最好的方法,并且我们有机会更好的了解类库的行为。
先前提到过,XML报表设计是JasperReport用来生成报表的初级材料(raw meterial)。这是因为XML中的内容需要被编译并载入到JasperDesign对象中,这些对象将在报表引擎向其中填入数据之前经过编译过程。
注意:大多数时候,报表的编译被划归为开发时期的工作。你需要编译你的应用程序报表设计,就像你编译你的Java源文件一样。在部署的时候,你必须将编译好的报表,连同应用程序一起安装到要部署的平台上去。这是因为在大多数情况下报表设计都是静态的,很少用应用程序需要提供给用户在执行期编译的,需要动态生成的报表。
报表编译过程的主要目的是生成并装载含有所有报表表达式(report expression)的类的字节码。这个动态生成的类将会被用来在装填数据,并给所有报表表达式求值(evaluate)的时候使用。具体例子是,如果你用IReport生成一个报表名字叫SimpleSheetTest,它的XML设计文件名叫SimpleSheetTest.jrxml,同时和它在同一目录下IReport会自动生成一个文件名为SimpleSheetTest.java,里面主要是一些报表元素,如Field,Parameters,Variables的定义,以及一些求值表达式。当然,像上面提到的,这个文件在你直接使用JasperReport API的时候是看不到的,因为它是在执行期生成的一个Class。要想看到它的办法是:在IDE(JBuilder,Eclipse)中单步执行程序,在报表打印的阶段,你将能跟踪到这个类,它的名字就是“你的报表名.java”,按上面的例子就是SimpleSheetTest.java,这和IReport是一致的。当然也可以像下面说的那样,到生成这个类的临时目录里找到它。
在这个类生成过程之前,JasperReport引擎需要验证报表设计的一致性(consistency),哪怕存在一处验证检查失败都不会继续运行下面的工作。在下面的章节,我将会展示报表设计验证成功之后的状况。
对于这个包含了所有报表表达式(report expressions)的类的字节码,我们至少需要关心三个方面的内容:
临时工作目录(temporary workingl directory)
Java编译器的使用:
Classpath:
为了能够编译Java源文件,这个文件必须被创建并且被保存到磁盘上。Java编译过程的输出是一个.class文件,这个包含所有报表表达式的类在这个工作目录里被创建并编译,这也是为什么JasperReport需要访问这个临时目录的原因。当报表的编译过程结束之后,这些临时的类文件将被自动删除,而生成的字节码将保存在net.sf.jasper.engine.JasperReport对象中。如果需要的话,这个类可以将自己序列化(serialized itself)并保存到磁盘上。这就是IReport的做法。
缺省情况下,这个临时工作目录就是启动JVM时的当前目录,这却取决于JVM的系统属性user.dir。通过更改系统属性jasper.report.compile.temp,用户可以很容易更改这个工作目录。在Web环境下,特别是当你不想让含有启动Web Server的批处理文件的目录和报表编译过程的临时工作目录混在一起的时候,修改这个属性就可以了。
上面提到的第二个方面涉及用来编译报表表达式类的Java编译器。首先,报表引擎将试图使用sun.tools.javac.Main类来编译Java源文件。这个类包含在tools.jar中,当且仅当这个jar文件在JDK安装目录下的bin/目录中,或在classpath中时,sun.tools.javac.Main才能正常使用。
如果JasperReport不能成功装载sun.tools.javac.Main文件,程序将动态执行java编译过程,就像我们通常用命令行那样,使用JDK安装目录下的bin/目录下的javac.exe。这就是为什么将JDK安装目录/lib/下的tools.jar文件copy到JasperReport工程的lib/目录下是一个可选的操作(optional operation)。如果tools.jar不在classpath中,JasperReport将显示错误信息并继续上面提到的操作。
当编译Java源文件的时候,最重要的事情莫过于classpath。如果Java编译器不能在指定的classpath中找到它试图编译的所有相关类的源文件,则整个过程将失败并停止,错误信息将在控制台显示出来。同样的事情也将发生在JasperReport试图编译报表表达式类的时候。所以,在runtime为编译过程提供正确的classpath是非常重要的。例如,我们我们需要确认在classpath中,我们提供了在报表表达式中可能用到的类(custom class)。
在这个方面也有一个缺省的行为。如果没有为编译report class特殊指定classpath,引擎将会使用系统属性java.class.path的值来确定当前的JVM classpath。如果你指定了系统属性jasper.reports.compile.class.path的值,你可以用你定义的classpath来覆盖缺省行为。
大多数情况下,编译一个report只需要简单的调用JasperReport类库中的JasperCompileManager.compileReport(myXmlFileName);即可。调用之后将生成编译好的report design并存储在.jasper文件中,这个文件将会保存在和提供XML report design文件相同的目录中。
第三步:Report Design 预览
JasperReport类库并没有提供高级的GUI工具来辅助进行设计工作。然而,JasperReport本身提供了一个很有用的可视化组件来帮助报表设计者在编译的时候预览报表设计(其实不如直接用IReport方便)。
net.sf.jasper.view.JasperDesigner是一个基于Swing的Java应用程序,它可以载入并显示XML形式或编译后的报表设计。尽管它不是一个复杂的GUI应用程序,缺乏像拖拽可视化报表元素这样的高级功能,但是它仍然是一个有用的工具(instrument)。所有JasperReport工程提供的例子都利用了这个报表查看器(report viewer)。
如果你已经安装了ANT(别告诉我你不知道什么是ANT),想要查看一个简单的报表设计(JasperReport工程所带例子),你只需要到相应的文件夹下输入如下命令:
〉ant viewDesignXML 或者 〉ant viewDesign
如果你没安装ANT,要达到上面的效果就不是很容易,因为JasperReport本身需要一些其他辅助的jar包(在JasperReport安装目录/lib下),在运行的时候,你需要把这些jar包都包含到你的classpath里面,并且正确设计系统属性,如上面提到的org.xml.sax.driver。我可以展示一下在windows下的例子:
>java -classpath ./;../../../lib/commons-digester.jar;
../../../lib/commons-beanutils.jar;../../../lib/commons-collections.jar;
../../../lib/xerces.jar;../../../lib/jasperreports.jar
-Dorg.xml.sax.driver=org.apache.xerces.parsers.SAXParser
dori.jasper.view.JasperDesignViewer -XML -FFirstJasper.xml
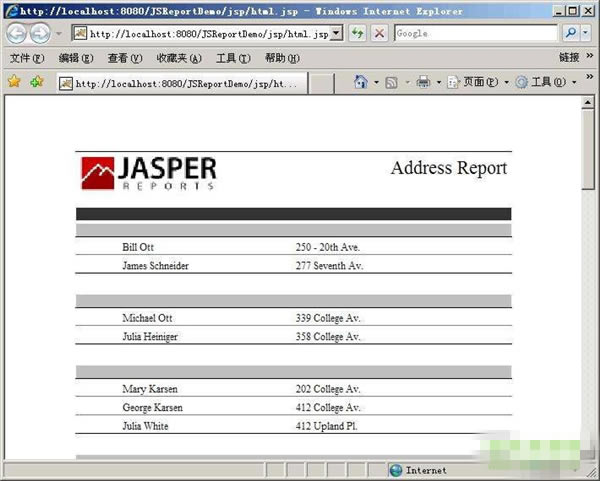
很麻烦吧?还是赶快弄个ANT吧。下面是预览之后的结果(其实用IReport更好)
第四步:报表装填(Filling Report)
报表装填(report filling)过程是JasperReport library最重要的功能。它体现了这个软件最主要的目的(main objective),因为这一过程可以自由的操作数据集(data set),以便可以产生高质量的文档。有3种材料需要装填过程中作为输入提供给JasperReport:
report design(reportl templet)
参数(parameters)l
数据源(datal source)
这一过程的输出通常是一个单一的最终要被查看,打印或导出到其他格式的文档。
要进行这一过程,我们需要采用net.sf.jasper.engine.JasperFillManager类。这个类提供了一些方法来让我们装填报表设计(report design),report design的来源可以是本地磁盘,输入流,或者直接就是一个已存在于内存中的net.sf.jasper.engine.JasperReport类。输出的产生是于输入类型相对应的,也就是说,如果JasperFillManager接到一个report design的文件名,装填结束后生成的report将会是一个放在磁盘上的文件;如果JasperFillManager收到的是一个输入流,则生成的report将会被写道一个输出流中。
有些时候,这些JasperFillManager提供的方法不能满足某些特定的应用的要求,例如可能有人希望他的report design被作为从classpath中得到的资源,并且输出的报表作为一个文件存放在一个指定的磁盘目录下。遇到这种情况时,开发人员需要考虑在将报表设计传递给报表装填过程之前,用net.sf.jasper.engine.util.JRLoader类来装载report design对象。这样,他们就能获得像报表名这样的report design属性,于是开发者就能生成最终文档的名字(construct the name of the resulting document),并将它存放到所需的位置上。
在现实中,有许多报表装填的情境(scenarios),而装填管理器仅试图覆盖其中最常被使用到的部分。然而对于想要自己定制装填过程的人来说,只要采用上面所说的方法,任何开发者都可以达到满意的结果。
报表参数通常作为java.util.Map的value提供给装填管理器,参数名为其键值(key)。
作为装填过程所需的第三种资源?数据源,有如下两种情况:
通常,引擎需要处理net.sf.jasper.engine.JRDataSource接口的一个实例,通过这个实例,引擎可以在装填过程中获取所需数据。JasperFillManager提供的方法支持所有的JRDataSource对象(这是一个Interface,上面一章提到过它的常用实现)。
然而,这个管理器还提供一些接受java.sql.Connection对象作为参数的方法集,来取代所需的数据源对象。这是因为在很多情况下,报表生成所需的数据都来源于某个关系型数据库中的表(table)。
在报表中,用户可以提供SQL查询语句来从数据库中取回报表数据(report data)。在执行期,engine唯一需要做的是获得JDBCconnection对象,并使用它来连接想要连接的数据库,执行SQL查询并取回报表数据。在后台,引擎将使用一个特殊的JRDataSource对象,但是它对于调用它的程序来说是透明的。
JasperReport工程提供了相关的例子,它们采用HSQL数据库服务器(在工程文件中,有一个相应的文件夹),要运行这些例子你需要首先启动该服务器,方法是:在/demo/hsqldb目录下输入如下命令:>ant 或者 >ant runServer
没装ANT就麻烦点:>java -classpath ./;../../lib/hsqldb.jar org.hsqldb.Server
一下代码片断显示了query例子是如何装填数据的:
//Preparing parameters
Map parameters = new HashMap();
parameters.put("ReportTitle", "Address Report");
parameters.put("FilterClause", "'Boston', 'Chicago', 'Oslo'");
parameters.put("OrderClause", "City");
//Invoking the filling process
JasperFillManager.fillReportToFile(fileName, parameters, getConnection());
第五步:查看报表(Viewing Reports)
报表填充阶段的输出通常是一个JasperPrint对象,如果把它保存在磁盘上,通常以一个.jrprint文件的形式存在。JasperReport拥有一个内置的查看器,用来查看用内置的XML导出器(XML exporter)获得的XML格式的报表文件。这个查看器就是以前提到过的net.sf.jasper.niew.JRViewer?一个基于Swing的应用程序组件,用户可以通过继承这个类来定制自己所需的查看器。JasperReport工程中自带的例子webapp中,你可以阅读JRViewerPlus类的代码来获取进一步内容。
注意:JasperViewer更像是一个教人们如何使用JRViewer组件的演示程序,这里要注意一点,当你调用JasperViewer的viewReport()方法来显示报表时,如果你关闭了预览Frame,整个应用程序将会随之结束,因为这个函数最后调用了System.exit(0);你可以通过继承这个类,并重新在你的Viewer里注册java.awt.event.WindowListener来避免这一情况的发生。
第六步:打印报表
JasperReport类库的主要目标,就是生成可打印的文档。而且多数应用程序生成的报表都是需要落实(或打印)到纸张上。我们可以用net.sf.jasper.engine.JasperPrintManager来打印JasperReport生成的文档。当然,报表也同样可以在被导出到其他格式如PDF,HTML之后再被打印。通过JasperPrintManager提供的方法,我们可以打印整个文档,打印单个文档或打印某一范围内的文档,可以显示打印对话框也可以不显示。下面的例子演示了不显示对话框,打印整个文档的方法:JasperPrintManager.printReport(myReport,false);
这个例子显示了如何打印5-11页的文档,同时显示打印对话框:net.sf.jasper.engine.JasperPrintManager.printPages(myReport,4,10,true);
第七步:导出报表
在一些应用程序环境下,将JasperReport生成的文档从其特有的格式导出到其他更为流行的格式如PDF,HTML是非常有用的。这样一来,其他人就可以在没有安装JasperReport的情况下查看这些报表,特别是当这些文档要通过网络发送出去的时候。
JasperReport提供了JasperExportManager类来支持此项功能。这项功能将会在以后不断加入对新的格式的支持。HTML和XML类型的文档,下面是导出的代码片断:JasperExportManager.exortReportToHtmlFile(myReport);
注意:想要将自己的报表导出到其他格式的用户,需要实现JRExporter的接口,或继承相应的JRAbstractExporter类。
第八步:对象的载入和保存
当使用JasperReport的时候,你经常会与序列化的对象,如以编译的报表设计,或已生成的报表打交道。有时,你需要手动载入从不同的source如input stream或你用类库核心功能(lib’s core functionality)产生的序列化类。JasperReport提供了两个特殊的工具类来提供上述操作的能力,这些类通常供报表引擎自己使用:
net.sf.jasper.engine.util.JRLoader
net.sf.jasper.engine.util.JRSaver
第一个类提供了一些方法让我们能够从不同类型的数据源如文件,URL,input stream和classpath里面获取序列化对象。最令人感兴趣的方法是loadObjectFormLocation(String)。它已经在上一章中介绍过了,这里不再赘述。
与上面的对象载入工具相反的部分是JRSaver类,它可以帮助程序员将自己的类序列化之后存放到本地磁盘或通过Output Stream发送到网络上去。
有时,开发人员可能想要载入已经生成好的report,或最终的已经被导出到XML格式的JasperReport文档,这与上面所说的直接load序列化对象有所不同。这时,我们需要载入的是将载入的XML内容进行编译,并生成JasperPrint对象,而并非仅仅是载入序列化对象。这时,我们可以通过net.sf.jasper.engine.xml.JRPrintXmlLoader类的一些静态方法,通过编译从XML文件中读取的内容构建出一个位于内存中的文档对象。
……
点击下载编程软件 >>本地高速下载
点击下载编程软件 >>百度网盘下载